이번에 리뷰할 논문은 Deep Hierarchical Classification for Category Prediction in E-commerce System 이라는 논문으로 알리바바에서 올해에 낸 논문입니다. 이 논문은 Classification 문제에서 Hierarchy가 존재할 경우에 좀 더 나은 방법으로 분류를 하기 위한 아이디어를 제시한 논문인데요. 쉽게 예를 들자면, 네이버 쇼핑에서 패션의류 내에 여성의류가 있고, 또 이 안에 니트나 블라우스 같이 여러개의 계층으로 이루어진 카테고리를 어떻게 분류하는 가에 대해서 다룬 논문이라고 할 수 있습니다.
최근에 제가 개인적으로 진행하고 있는 모바일 어플리케이션 제작 프로젝트에서 카테고리에 계층이 있는 문제를 풀 수 있는 딥러닝 모델을 학습시키기 위해 공부하던 중 알게 된 논문인데요. 기존의 단일 계층 분류 문제에서 간단한 아이디어를 통해서 계층이 있는 분류 문제에도 적용할 수 있는 아이디어를 고안해 낸 것이 이 논문의 핵심이라고 할 수 있습니다. 앞서 언급했듯이, 그리고 논문 제목에서도 있듯이 E-Commerce 같은 분야에서도 적용을 할 수 있는 방법이고 이러한 계층이 있는 분류문제는 이 외에도 실생활에서 많이 찾을 수 있을 것입니다. 그래서 이 논문에 대해서 정리하므로써 이 글을 읽는 분들이 겪고 있는 문제에 도움이 되었으면 합니다.
Introduction
일반적으로 컴퓨터 비전에서의 이미지 분류는 CIFAR-10, ImageNet과 같이 이미지를 정해진 개수의 카테고리로 분류를 하는 문제입니다. 이러한 문제들은 이미지가 정해진 한 계층의 카테고리로 나뉘고 이를 분류하는 모델을 학습시키는게 기존의 문제라고 할 수 있습니다. 하지만 현실에서의 문제는 단순히 카테고리가 하나의 계층으로만 나누어지지 않습니다. 예를 들어 네이버 쇼핑과 같은 E-Commerce의 분야에서는 패션의류라는 카테고리의 아래에 여성의류와 남성의류의 하위 계층의 카테고리고 나뉘고, 여성의류는 다시 니트나 블라우스와 같은 더 세부적인 카테고리로 나뉘게 되는 경우를 생각할 수 있습니다. 그리고 이러한 문제를 기존의 Classification Task (분류 문제)와 비교해서 Hierarchical Classification Task (계층 분류 문제)라고 불리게 됩니다.
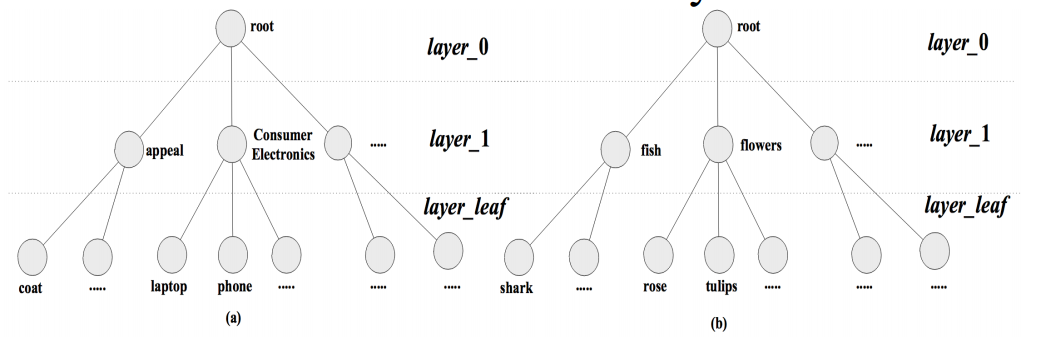
Hierarchical Classification은 기존의 분류 문제와 다르게 두가지 과제가 있는데요. 하나는 모델이 계층구조를 어떻게 포함할 것인가 (Hierarchical representation in classification model), 그리고 다른 하나는 학습과정에서 이러한 계층 정보를 어떻게 학습에 이용할까 (Hierarchical inconsistency in training process) 입니다. 그리고 이 논문에서는 이를 해결하기 위한 아이디어로 Deep Hierarchical Classification (DHC) 라는 프레임워크를 통해 모델이 계층 정보를 포함하게 하는 방법과 Loss 함수에 새로운 Layer loss와 Dependence loss를 추가시키는 방법을 소개합니다.
Deep Hierarchical Classification
먼저 이 논문을 이해하기 위해서는 DHC (Deep Hierarchical Classification)에 대해서 이해할 필요성이 있습니다. DHC에 좀 더 설명하기에 앞서서 이를 수학적으로 표현하면 다음과 같이 나타낼 수 있습니다.

복잡해보이지만 이해를 하면 굉장히 단순합니다. 즉, 입력으로는 분류를 데이터 (이미지나 텍스트 분류를 생각해 볼 수 있겠죠!)를 주면 Categorical Tree 내에서 Root부터 시작해서 Leaf 노드에 닿을 때까지의 계층에 대해서 각각 (서브) 카테고리를 예측하는 것입니다. 앞선 네이버 쇼핑의 예시를 여성 블라우스 예시를 들어보자면, 이는 첫 번째 레이어 (Y1) 에서는 패션의류라는 카테고리를 가질 것이고 두 번째 레이어 (Y2) 에서는 여성의류, 그리고 마지막 레이어에서는 (Y3) 블라우스라는 카테고리를 가지게 되겠죠. 그렇다면 결과적으로는 아웃풋으로는 어떤 카테고리가 정답이 될까요? 정답은 단순합니다. 목적에 따라 필요로 하는 게 다르게 되겠죠. 예를 들어 의상이 블라우스인지 원피스인지와 같은 단순한 분류를 목적으로 한다면 마지막 레이어 (Y3) 의 결과만을 이용하면 될 것이고, 이 옷이 남성의류인지 여성의류인지만을 구분하는 것을 목적으로 한다면 첫 번째 레이어 (Y1) 의 결과만을 필요로 하겠죠.
그렇다면 이러한 계층을 나누는게 의미가 있을까요? 어짜피 하나의 레이어만 결과로 이용하는 것이 아닌지에 대해 의문을 가질 수 있습니다. 결과적으로는 이러한 계층이 잘 나뉘어져 있다면 의미가 있습니다. 왜냐하면 학습과정에서 계층간의 관계를 통해 성능을 더 향상시킬 수 있기 때문입니다. 예를들어 블라우스라는 이미지가 들어왔을 때에 이것이 음식, 가전제품이 아니고 패션의류라는 힌트, 그리고 남성의류가 아니고 여성의류라는 힌트가 있으면 하나의 레이어만 사용하는 것보다 좀 더 많을 정보를 활용할 수 있기 때문입니다.
아래 그림은 이 논문에서 사용된 모델의 아키텍처를 설명하는 그림입니다. 이 그림을 자세히 보시면 계층의 정보가 어떻게 표현되었는지 관찰하실 수 있습니다.
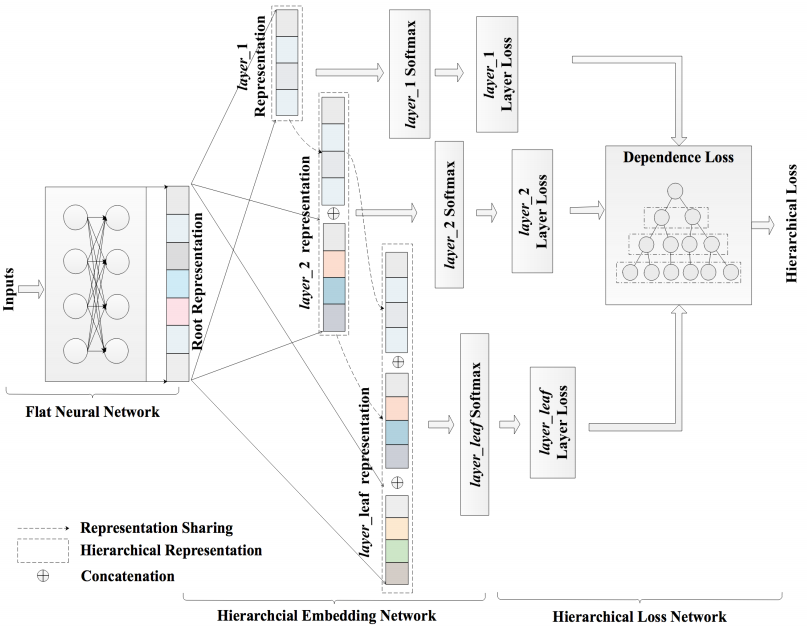
이 그림을 설명하기 위해서는 세 가지 부분으로 나눠서 설명할 수 있습니다. 각각 Flat Neural Network (FNN), Hierarchical Embedding Network (HEN), 그리고 남은 하나는 Hierarchical Loss Network (HLN) 입니다. 그리고 이 세 가지에 대해 이해한다면 이 논문의 핵심을 이해했다고 할 수 있을 것입니다.
Flat Neural Network (FNN)
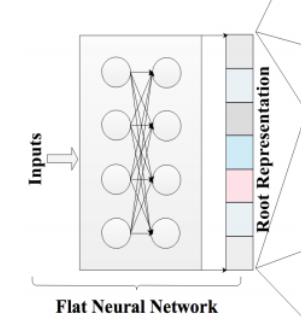
먼저 Flat Neural Network (FNN)은 일종의 Backbone Network라고 볼 수 있습니다. 즉 모델의 인풋 (이미지나 텍스트)가 있을 때에 이에 대한 Representation을 뽑아내는 네트워크입니다. 그리고 이러한 representation을 활용해 이후 분류작업을 진행하게 됩니다. 만약에 이미지 분류를 하는 문제라면 Flat Neural Network로는 ResNet, EfficientNet이나 MobileNet 등이 사용될 수 있겠죠.
Hierarchical Embedding Network (HEN)
다음은 Hierarchical Embedding Network (HEN)입니다. HEN은 카테고리에서 각 계층들에 대한 representation을 새로 구하는 것이라고 볼 수 있습니다. 예를 들어서 여성 블라우스의 경우 옷임을 판별하기 위한 representation, 남성 옷인지 여성 옷인지를 구분하기 위한 representation, 그리고 정확히 어떤 종류의 옷인지를 판별하는 representation이 독립적으로 있다는 것입니다.

특히 이 논문에서는 각각의 representation을 구할 때 상위 계층의 representation을 하위 계층이 포함할 수 있도록 하여 계층 간의 정보가 잘 전달되도록 구현하였다는 것이 특징이라고 할 수 있습니다. 구체적으로는 아래의 식과 같이 상위 계층의 representation을 하위 계층의 representation을 구할 때 concatenate 하는 방식으로 구현되어 있는 것을 볼 수 있습니다.

Hierarchical Loss Network (HLN)
마지막으로는 Hierarchical Loss Network (HLN) 입니다. 이에 대해 간단히 요약하면 계층간의 포함관계를 모델의 손실함수에 직접적으로 포함시키기 위한 시도라고 할 수 있습니다. 이는 Loss를 구할 때에 dependence loss를 추가하는 방식으로 구현되었는데 식은 아래와 같습니다.

이 식을 이해하기 위해서는 $D_l$과 $I_l$에 대해서 이해를 할 필요가 있습니다. 먼저 $D_l$은 $l-1$ 계층의 카테고리가 $l$ 계층의 카테고리를 포함하지 않을 때에만 1이 되는 값입니다. 이를 통해서 $D_l$은 상위 계층이 하위 계층을 포함하지 않을 때 loss를 높이는 데에 영향을 주고 이에 따라서 $ploss$의 값이 0부터 1사이의 값이라는 것도 짐작할 수 있습니다.
마찬가지로 $I_l$은 $l$ 번째 계층의 prediction이 정답일 때에 1이 되고 정답이 아닐 때에 0이 되는 값입니다. $l$ 번째 계층 자체의 모델 결과가 정답이라면 0이되어 $ploss$에 0승을 하면 0이 되므로 loss가 낮게 나오고, 계층 자체의 예측이 틀려서 1이 된다면 $D_l$의 값에 따라서 $l-1$ 번째 계층과 $l$ 번째 계층 간의 관계에 따라서 loss가 정해지게 되는 것입니다.
이에 대한 직관을 얻으셨으면 이 dependence loss가 왜 작동하는 지 이해하실 수 있을 것입니다. 이후에는 이 dependence loss와 각 계층에서의 일반적인 cross entropy loss를 더하여 최종 loss가 완성되게 됩니다.
Conclusion
이 논문을 읽고 계층이 있는 Classification문제를 어떤 방식으로 접근하는 지에 대해서 어느 정도 방법을 알 수 있었습니다. 물론 이 논문이 다른 방법론들을 대체하는 것은 아니지만 계층 간의 관계를 어떻게 해석할 지에 대해서나, 혹은 실제 구현을 한다면 어떻게 해야할 지에 대한 이해를 얻을 수 있었습니다.
논문에서는 ploss가 상수로 정할 수 있다고 하였는데 아직 이에 대해서는 이해하기 못하였습니다. ploss를 상수로 두면 역전파 알고리즘을 적용했을 때에 모델에 전파되는 값이 없는데 이 방법이 가능한지 모르겠네요.