오래전부터 컴퓨터 비전 분야를 공부하면서, 내가 혼자서 공부한 것들을 정리할 기회가 잘 없었습니다. 스스로 노트로 정리를 하더라도 어느 순간 뒤돌아보면 정리한 것을 찾을 수 없는 경우도 많았고, 뒤돌아봤을 때 논문의 내용의 부분부분이 다시 이해가 안되는 경우도 있었고요. 그래서 이번 기회에 제가 예전에 읽었던 논문들을 다시 되돌아보고 정리하기 위해서 컴퓨터 비전 분야의 대표적인 논문들을 정리해보는 시간을 갖기로 하였습니다. 또한 이미 인터넷에 정리된 글들이 많기 때문에, 제가 정리한 내용들은 논문들을 읽으면서 제가 느낀 핵심이나 인사이트 위주로 제 생각들을 정리해보려고 합니다. 그러므로써 기존에 공부를 안하셨던 분들은 논문의 핵심에 대해서 이해를 할 수 있고, 기존에 논문들을 알고 있는 분들도 제가 직접 논문을 공부하면서 느낀 점들에 대해서 공유하고 인사이트를 얻어 가셨으면 하는 마음에 이 글을 작성하게 되었습니다.
또한 이 글에서 다룰 내용은 고전적인 컴퓨터 비전에 대한 설명보다는 딥러닝을 이용한 방법론, 그리고 이미지 분류라는 분야에 대한 논문들을 다룰 예정입니다. 물론 제가 컴퓨터 비전 분야에 오랫동안 공부하면서 고전적인 방법론들에 대해서도 설명을 드릴 수는 있지만, 이해를 위해서 고전적인 방법론들에 대한 설명은 자세하게 하지 않을 예정입니다. (물론 기회가 된다는 다른 글들을 통해서 중요하다고 생각하는 내용들을 차차 포스팅 해 가겠습니다.)
AlexNet
제일 처음 소개드릴 논문은 AlexNet 입니다. 원 논문의 제목은 ImageNet Classification with Deep Convolutional Neural Networks 이고 이미지 분류의 문제에서 최초로 딥러닝 모델을 안정적으로 학습시켰다는 데에서 큰 의미가 있다고 생각합니다.

모델의 아키텍처는 다음과 같이 두 개의 parallel한 CNN (Convolutional Neural Network) 아키텍처를 이용한 후 마지막 Classification 직전에 두 representation을 합치는 방식을 이용합니다. 논문을 읽어보면 아시겠지만 이렇게 두 개의 평행한 아키텍처를 이용한 것은 당시에 GPU 메모리에 모델을 한번에 담을 수 없기 때문입니다. 따라서 논문의 큰 맥락을 이해하기 위해서는 자세하게는 몰라도 큰 문제가 없다고 할 수 있고, 단순히 CNN 레이어들을 쌓아서 만든 아키텍처라고 이해하면 될 것 같습니다.
그럼에도 이 아키텍처가 의미가 있는 것은 기존에 딥러닝 문제에서 풀지 못했던 Gradient Vanishing과 같은 문제를 해결했기 때문입니다. 이것은 바로 이 아키텍처에서 이제는 모두가 알만한 ReLU (Rectified Linear Unit) Activation 함수를 사용했기 때문이라고 할 수 있습니다.

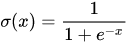


먼저 ReLU Activation을 설명하기 위해서 기존에 쓰이던 대표적인 Activation 함수인 Sigmoid와 Tanh Activation 함수를 이해할 필요가 있습니다. 이 함수들은 기존에 주로 쓰이던 Activation 함수들인데요. 이러한 함수들에는 Gradient Vanishing이라는 큰 문제점이 존재합니다. 딥러닝 모델의 경우 모델 파라미터들 Back Propagation 알고리즘을 통해서 업데이트 시키는데, 이는 곧 모델이 깊어질수록 Activation 함수들의 미분값이 계속 곱해지게 됩니다. 그런데 Sigmoid나 Tanh 함수같은 경우에 입력값이 양 끝으로 갈수록 미분값이 0에 가까워지기 때문에 미분값들의 곱이 0에 가까워지고 결국 이렇게 축적된 Gradient가 매우 작아서 모델 파라미터를 거의 업데이트 시키지 않게 되는 문제가 생기는 것입니다.

따라서 이 논문에서는 고질적으로 딥러닝 모델들이 가지고 있던 Gradient Vanishing 문제를 ReLU Activation을 통해서 해결하려 합니다. ReLU 함수의 형태는 위와 같습니다. 항상 미분 값이 0과 1이기 때문에 미분값을 아무리 곱해도 Gradient Vanishing문제가 생기지 않는 것입니다. 여기서 조금 더 관찰하면 미분값이 0인 음수부분이 이상하게 느껴질 수도 있습니다. 맞습니다. 실제로 모델이 싶어질수록 ReLU 함수의 입력이 음수여서 Activation 결과가 0인 Dead ReLU 현상이 심해집니다. 그래서 이후에 다른 여러 Activation 함수들이 등장하지만 이에관한 얘기는 추후에 다루도록 하겠습니다.
이 외에도 원 논문에서는 Local Response Normalization이나 Overlapping Pooling등의 방법을 추가적으로 사용합니다. 하지만 이러한 방법들은 후속 연구들에서 성능에 크게 영향을 주지 않는 다는 것들이 실험적으로 증명이 되었고 이 논문의 핵심에서 벗어난다고 생각하여 다루지 않았습니다. 하지만 저는 원 논문을 통해서 이러한 점을 직접 읽어보고 왜 이런 방법을 사용했을까하는 인사이트를 얻어가시길 강력히 추천드립니다.
VGGNet
다음에 소개드릴 논문은 VGGNet입니다. 이 모델의 논문은 Very Deep Convolutional Networks for Large-Scale Image Recognition 입니다. 이 논문은 바로 다음에 다뤄드릴 GoogleNet과 함께 네트워크의 깊이를 늘려서 모델의 성능을 높이고자 하는 시도라고 할 수 있습니다. 먼저 모델 아키텍처는 다음과 같습니다.


위 논문에서는 총 6개의 네트워크를 학습시키고 비교실험을 진행합니다. 이에 대한 내용도 흥미롭기 때문에 읽어보시기를 추천드리고 여기서는 제가 느낀 이 논문의 핵심 포인트에 대해서 설명드리겠습니다.
앞서 설명드렸듯이 이 연구에서는 네트워크를 깊게 만들어서 모델의 성능을 높이기위한 시도를 했다고 말씀드렸습니다. 그리고 그러한 노력의 핵심이 이 논문의 핵심이라고 생각합니다. 네트워크 구조를 자세히 관찰하시면 이미 눈치를 챘을 수도 있겠지만, 이 논문의 포인트는 모델 전체를 통틀어서 3x3의 작은 receptive field를 가진 Convolution Layer를 쌓아올린 것이라고 할 수 있습니다. 논문의 표현을 빌리자면 5x5 Convolution을 한번 사용하는 것은 3x3 Convolution을 두 번 사용했을 때와 같은 receptive field를 가지고 있고, 또한 7x7 Convolution을 한번 사용하는 것은 3x3 Convolution을 세 번 쌓아올린 것과 동일한 receptive field를 가집니다. 그리고 이렇게 작은 Convolution을 쌓음으로써 연산량을 줄임과 동시에 네트워크를 깊게 만들 수 있는 것입니다.
결국 이러한 방식으로 VGGNet은 네트워크를 깊게 만들어서 성능을 크게 올릴 수 있었습니다. 여기서 한 가지 인사이트를 주자면 깊은 네트워크를 가진 모델이 있을 때에 네트워크의 처음 부분과 네트워크의 마지막 부분이 각각 무엇을 학습하는 지 알아보는 것도 중요합니다. 결론부터 말하면 네트워크의 초기 부분에서는 이미지의 Low Level feature들이 학습이 되고 네트워크의 마지막 부분에서는 High Level feature들이 학습이 됩니다. 즉 네트워크가 깊어질 수록 receptive field가 커지고, 이는 곧 네트워크가 이미지의 큰 부분을 보고 분석을 한다는 것을 의미합니다. 반대로 네트워크의 초기 부분에서는 receptive field가 3x3이나 5x5처럼 작으므로 이미지의 Local feature들에 대한 분석이 이루어 진다고 할 수 있습니다.
이러한 특징은 컴퓨터 비전에서 딥러닝 모델을 이해하기 위한 중요한 요소이기도 하며, 이후에 Style Transfer을 위한 GAN 모델을 리뷰할 때에도 설명할 내용이니 인사이트를 얻어가시면 좋겠습니다.
GoogLeNet
다음은 마찬가지로 네트워크의 깊이를 깊게 만들어서 모델을 성능을 끌어올리려 시도했던 GoogleNet이라 부르는 모델입니다. 이 논문의 원제는 Going Deeper with Convolutions 이며 VGGNet과 함께 ImageNet Challenge 2014에 참가하여 Error Rate에서 1위를 차지한 모델이기도 합니다. 네트워크 아키텍처를 먼저 보여주고 이에 대한 설명을 이어나가겠습니다.

GoogLeNet의 아키텍처를 살펴보면 VGGNet과 마찬가지로 레이어를 깊게 쌓아올렸다는 것을 관찰할 수 있습니다. 그리고 또 한가지 특징이 있는데 중간 Activation Map (빨간색)이 동시에 parallel한 여러개의 레이어와 연결되어 있다는 것입니다. 이 부분이 저는 VGGNet과 비교되는, 그리고 이 논문의 핵심적이 아이디어라고 생각하기 때문에 이에 대해서 조금 더 설명을 하겠습니다.
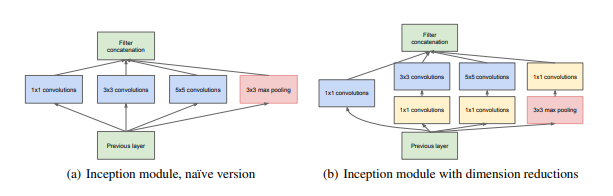
이 논문에서는 한가지 Activation Map이 여러개의 레이어를 parallel하게 거쳐서 하나의 Output Activation Map을 만드는 것을 Inception 모듈이라 지칭합니다. 그리고 이러한 Inception 모듈의 특징은 하나의 입력을 다수에 서로 다른 크기의 convolution 레이어, 혹은 다른 연산을 이용한다는 것입니다. 이러한 방법은 Network in Network에서 영감을 받은 것인데 하나의 네트워크 안에서 또 다시 여러개의 parallel한 작은 모듈(네트워크)를 이용하는 것입니다. 이러한 방식이 어떤 효과를 가지는 지는 위의 기본 Inception module을 예로 들어 설명하겠습니다.
위의 그림을 보면 이전 레이어로부터 받은 Activation Map을 1x1, 3x3, 5x5 Convolution, 그리고 3x3 Max Pooling 연산을 동시에 수행하는 것을 볼 수 있습니다. 그리고 이 것은 Inception Module에 들어가는 입력에 대해서 다양한 receptive field를 가진 Convolution을 수행하므로서 다양한 receptive field에 대한 분석을 동시에 진행하게 되는 효과를 가지게 됩니다. 따라서 입력값으로 부터 좀 더 풍부한 특징들을 찾아낼 수 있다는 것입니다.
그림 (b)는 naive한 Inception 모듈의 파라미터를 줄이기 위한 시도라고 볼 수 있습니다. 3x3, 5x5 Convolution을 적용하기 전에 1x1 Convolution을 활용하여 channel의 개수를 줄임으로서 연산적인 부분에서 이득을 보기 위한 설계하고 할 수 있습니다.
ResNet
다음 논문은 Skip Connection으로 유명한 ResNet입니다. 원 논문은 Deep Residual Learning for Image Recognition 입니다. ResNet의 가장 큰 핵심은 기존 모델들과 다르게 Residual을 학습한다는 것입니다.

Residual을 학습한다는 것은 위 그림으로 설명할 수 있습니다. 앞서 설명한 AlexNet, VGGNet, 그리고 GoogLeNet은 Convolution 레이어들은 공통적으로 입력값이 Convolution 레이어를 거쳐서 결과값으로 바로 전달되는 형태였습니다. 이는 위의 표현을 빌리자면 입력값 x가 Convolution 레이어인 weight layer들을 거쳐서 결과인 F(x)로 나오는 것입니다. 하지만 이런 방식에는문제점이 존재합니다. 바로 네트워크가 깊어질 수록 그레디언트가 곱해지면서 그레디언트가 사라지는 Gradient Vanishing문제가 존재한다는 것이지요. 앞서 설명을 잘 따라오셨다면 AlexNet 에서 ReLU Activation 함수를 사용하므로써 Gradient Vanishing 문제를 해결하려 했다는 사실과 충돌이 있다고 느껴질 수 있습니다. 하지만 ReLU 함수를 사용하더라도 네트워크가 매우 깊어지게 되면 Gradient가 무수히 많이 곱해지므로서 Gradient가 사라지는 문제가 여전히 존재하게 됩니다. 그래서 ResNet에서는 이러한 문제를 해결하기 위해서 그림 (b)와 같이 입력값을 최종 결과에 그대로 더해주는 전략을 취해주게 됩니다. 결국 입력값을 그대로 더해주므로써 네트워크는 결과와 F(x) + x, 입력값 x의 차이, 즉 Residual만을 학습하고도록 하여 최소한의 Gradient가 네트워크 아래까지 전달될 수 있도록 한 것입니다.
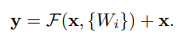
위 그림을 식으로 나타내면 위와 같이 나타낼 수 있는데, 이를 x로 미분했을 때에 항상 1이 남기 때문에 Gradient가 잘 흘러갈 수 있는 것입니다. 가령 F(x, {W_i})의 값이 0이 된다고 해도 상관없습니다. 그냥 값을 그대로 주는 레이어로 남기 때문에 결과적으로 불필요한 레이어가 될 지언정 학습에 방해가 되지 않을 뿐더러 네트워크를 더 깊게 만들 수 있다는 장점이 있기 때문입니다.
결과적으로 ResNet은 이러한 방법을 통해서 레이어를 101개 그리고 152개 등 매우 깊은 네트워크를 만들 수 있었고, 결과적으로 모델을 성능을 높게 끌어올릴 수 있었습니다.
DenseNet
다음으로 소개시켜드리고자 하는 논문은 Densely Connected Convolutional Networks 이고 이 모델은 DenseNet이라고 불리웁니다. 이 논문의 핵심은 이전 레이어의 feature map을 ResNet과 마찬가지로 다음 레이어와 연결하는 것이라고 할 수 있습니다. 둘의 차이점은 아래 그림을 먼저 보여드리고 설명해드리겠습니다.

ResNet과 DenseNet의 차이점은 먼저 이전 레이어의 feature map이 바로 다음 모듈에만 연결되는 것이 아니고 이어디는 모듈에 계속 연결된다는 것입니다. 이러한 방식으로 DenseNet은 이전 레이어의 정보를 계속 넘겨줄 수 있게 하여 성능을 높인 것입니다. 또 ResNet과 다른 또 하나의 차이점은 DenseNet에서는 더하는 방식이 아니라 Concatenation의 형태로 이전 레이어의 정보를 전달했다는 것이라고 할 수 있습니다.
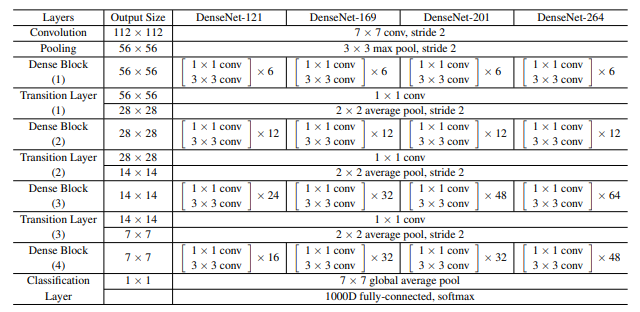
이러한 방식으로 DenseNet도 네트워크의 깊이를 깊게 쌓으면서 이전 feature map의 정보를 최대한으로 활용할 수 있었고, 성능도 더 높일 수 있었다고 볼 수 있습니다.
정리
이번에는 딥러닝이 컴퓨터비전에 적용된 초창기의 유명한 논문들을 순서대로 알아보았습니다. 제가 생각하는 논문의 핵심 위주로 설명하고 너무 구체적이고 지엽적인 내용은 제외하려고 노력하였으며, 이 글을 통해서 인사이트를 얻어가셨으면 합니다.
앞으로도 다른 주제로 계속 논문 리뷰를 해드릴 예정이고 피드백 환영합니다.
Reference
http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf
https://en.wikipedia.org/wiki/Activation_function
https://arxiv.org/abs/1409.1556
https://arxiv.org/abs/1409.4842
https://neurohive.io/en/popular-networks/vgg16/
https://arxiv.org/abs/1512.03385